こんにちは!LDHファン歴10年、アイデミーのSchwimmerです。
EXILEをはじめとした、芸能事務所「株式会社LDH JAPAN」に所属するアーティストは、10年前と比較して、メディアへの露出がとても多くなったと思います。しかし、私の身の回りではまだ「みんな同じに見える……」とか「誰がどのグループに所属しているかわからない~」といった声を耳にします。
そこで、今回はLDHを代表するグループ、EXILE、EXILE THE SECOND、三代目 J SOUL BROTHERS from EXILE TRIBE、GENERATIONS from EXILE TRIBEに所属する総勢24名をCNNおよび転移学習によって顔分類し、どこのグループに所属するかも併せて出力したいと思います。
導入
まずは、LDHに精通されていない方のために、グループ構成を紹介したいと思います。
EXILE ATSUSHI、EXILE AKIRA、EXILE TAKAHIRO、橘ケンチ、黒木啓司、EXILE TETSUYA、EXILE NESMITH、EXILE SHOKICHI、EXILE NAOTO、小林直己、岩田剛典、白濱亜嵐、関口メンディー、世界、佐藤大樹
橘ケンチ、黒木啓司、EXILE TETSUYA、EXILE NESMITH、EXILE SHOKICHI、EXILE AKIRA
- 三代目 J SOUL BROTHERS from EXILE TRIBE(7名)
NAOTO、小林直己、ELLY、山下健二郎、岩田剛典、今市隆二、登坂広臣
- GENERATIONS from EXILE TRIBE(7名)
白濱亜嵐、片寄涼太、数原龍友、小森隼、佐野玲於、関口メンディー、中務裕太
詳しく知りたい方はこちらで名前と顔を照らし合わせてみてください!
このようにLDHではメンバーが複数のグループを掛け持ちしていることもあり、誰がどこのグループ所属かよくわからない方が多いのも、致し方ないのかなと思います。
転移学習とは
ここでは、今回用いる転移学習について説明します。
機械学習において、0から学習して高精度な予測を行うには、場合によって数十万~数百万という学習データを要することもあります。また、現実的に大量のデータを収集することが困難なケースも多く、学習データのラベル付けも必要となるため、機械学習を完了させるまでには相当な時間とコストがかかってしまいます。
例えば、畳み込みニューラルネットワーク(CNN)で、画像認識などを1からモデル構築するとなると、大量のサンプル画像を集めなければならず、さらに学習にも多くの時間がかかります。
この時間とコストを少なくするために、あらかじめ大量のデータを使って学習を行ったモデルを、別のものにも使い回すという「転移学習」が用いられます。これにより、限られたデータの中でも精度の高い予測を行うことができるようになります。
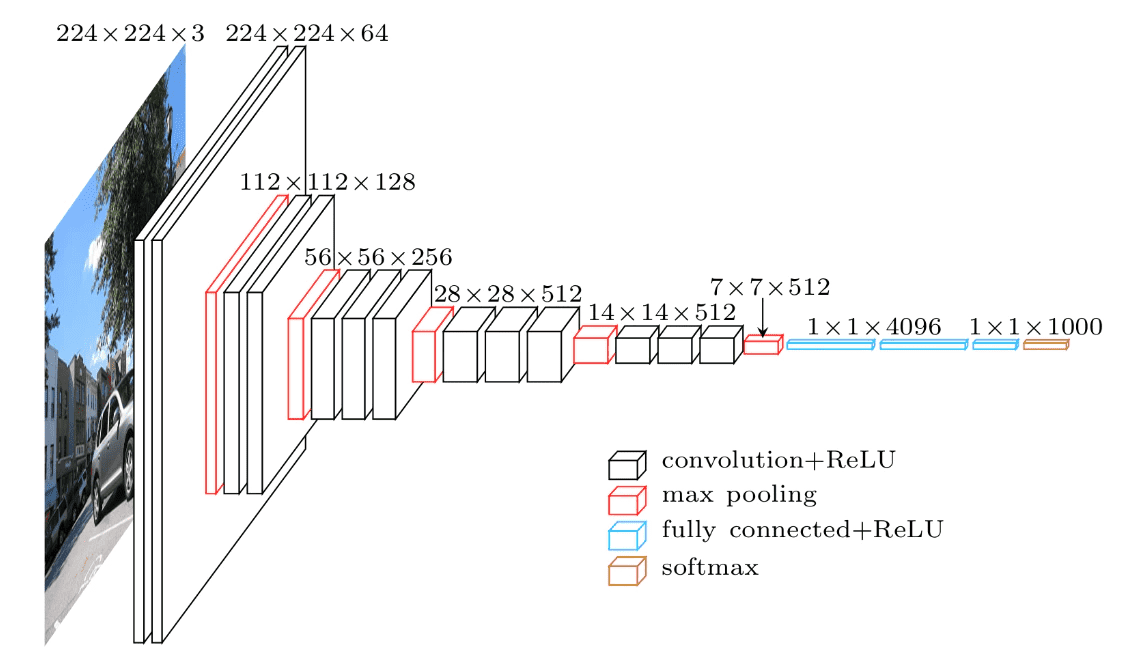
今回は、ImageNet(120万枚,1000クラスからなる巨大な画像のデータセット)で学習した画像分類モデルの一つであるVGG16というモデルを使用します。VGG16は、13層の畳み込み層と3層の全結合層の計16層からなります。
今回の実装では、VGG16の全結合層を外して新たに全結合層を追加し、16層以降のみを学習させます。CNNにおいて、浅い層では縦線・横線などのおおよその特徴を抽出し、深い層(VGG16の16層以降など)では、その画像特有の特徴を抽出することがわかっています。つまり、深い層を取り外し、浅い層を再利用することで効率よく転移学習することができます。
これによって、VGG16の高い特徴量抽出を継承しつつ、少サンプル・短時間で精度の高い学習モデルを構築できます。
手順
- 画像収集
- 集めた画像から、顔部分を切り抜く
- 画像の水増し
- 学習
- テスト
準備
画像収集
まず、EXILE、三代目 J SOUL BROTHERS from EXILE TRIBE、GENERATIONS from EXILE TRIBEに所属するアーティストの画像を200枚ずつ集めました。今回、収集するアーティスト画像が計24名分にも及ぶため、PythonのライブラリであるBeautifulSoupを使ったスクレイピングではなく、より簡単に画像を集められるicrawlerというライブラリを使いました。
from icrawler.builtin import BingImageCrawler
class_ = [""]
for name in class_:
crawler = BingImageCrawler(storage={"root_dir": name})
crawler.crawl(keyword = name, max_num=200)
顔領域の検出
次に、集めたメンバーの画像から顔領域部分を検出したいと思います。人間の顔を検出する分類器を自分で作ることも可能なのですが、1から作るのはなかなか大変です。しかし、PythonではOpenCVをインストールすると、デフォルトで顔や目などを分類することができるカスケード分類器が付随してくるため、今回はその中のhaarcascade_frontalface_default.xmlを用いて顔検出を行いたいと思います。
import cv2
import matplotlib.pyplot as plt
from PIL import Image
import os, glob, sys
import numpy as np
class_ = [""]
def get_file(dir_path):
filenames = os.listdir(dir_path)
return filenames
for name in class_:
in_jpg = "./" +name+"/"
out_jpg = "./face/"+name
os.makedirs(out_jpg, exist_ok=True)
pic = get_file(in_jpg)
for i in pic:
image_gs = cv2.imread(in_jpg + i)
cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=1,minSize=(1,1))
cnt = 1
for x,y,w,h in face_list:
dst = image_gs[y:y+h,x:x+w]
save_path = out_jpg + '/' + 'out_(' + str(i) +')' +str(cnt) +'.jpg'
a = cv2.imwrite(save_path, dst)
plt.show(plt.imshow(np.array(Image.open(save_path))))
cnt += 1
このカスケード分類器を使っても、顔以外のものや検出対象者以外の顔が検出されてしまうため、これらについては手作業によって削除しました。24人もいたため、この作業だけで2日間ほどかかってしまいました。
その後、顔検出した画像のサイズを64×64にリサイズし、名前ごとにfaceディレクトリに保存しました。
データの分割
これまで画像データの整理を行ってきましたが、ここで画像データを学習データとテストデータに分類します。テストデータに全データのうちの2割(40枚)のデータをランダムに振り分けます。
import shutil
import random
import glob
import os
class_ = [""]
os.makedirs("./test", exist_ok=True)
for name in class_:
in_dir = "./face/"+name+"/*"
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./face/"+name+"/")
random.shuffle(in_jpg)
os.makedirs('./test/' + name, exist_ok=True)
for t in range(len(in_jpg)//5):
shutil.move(str(in_jpg[t]), "./test/"+name)
振り分けられたテストデータはtestディレクトリに保存します。
学習データの水増し
全データからテストデータを差し引いた160枚では学習を行うには足りないため、画像データの水増しを行います。画像の中には、顔が傾いている写真が含まれていることもあるので、左右15度に回転処理を行ったのち、閾値処理、ぼかし処理を行い、学習データ画像を9倍に水増ししました。
import os
import matplotlib.pyplot as plt
import cv2
import glob
from scipy import ndimage
class_ = [""]
for name in class_:
in_dir = "./face/"+name+"/*"
out_dir = "./train/"+name
os.makedirs(out_dir, exist_ok=True)
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./face/"+name+"/")
for i in range(len(in_jpg)):
print(str(in_jpg[i]))
img = cv2.imread(str(in_jpg[i]))
for angle in [-15,0,15,]:
img_rot = ndimage.rotate(img,angle)
img_rot = cv2.resize(img_rot,(64,64))
fileName=os.path.join(out_dir,str(i)+"_"+str(angle)+".jpg")
cv2.imwrite(str(fileName),img_rot)
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(out_dir,str(i)+"_"+str(angle)+"thr.jpg")
cv2.imwrite(str(fileName),img_thr)
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
fileName=os.path.join(out_dir,str(i)+"_"+str(angle)+"filter.jpg")
cv2.imwrite(str(fileName),img_filter)
水増しにより1人当たり160×9の1440枚の学習データを得ることができました。
これらは学習用データとしてtrainディレクトリに保存します。
実装
今回、画像分類をするという目的とともに、転移学習の有無での精度の比較も行いたいと考えました。そのため、0から畳み込みニューラルネットワークを学習させる場合と、ImageNet(120万枚,1000クラスからなる巨大な画像のデータセット)で学習した画像分類モデル(今回扱うのはVGG16)とその重みを用いて転移学習した場合の2パターンで画像分類を行います。
また、参考までに水増し作業なしで転移学習を行った場合も比較したいと思います。
畳み込みニューラルネットワーク(CNN)
まず、0から自分のモデルのみで畳み込みニューラルネットワークを学習させる場合のコードを下記に記載します。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
names = [""]
X_train = []
Y_train = []
for i in range(len(names)):
img_file_name_list=os.listdir("./train/"+names[i])
print(len(img_file_name_list))
for j in range(0,len(img_file_name_list)-1):
n=os.path.join("./train/"+names[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_train.append(img)
Y_train.append(i)
X_test = []
Y_test = []
for i in range(len(names)):
img_file_name_list=os.listdir("./test/"+names[i])
print(len(img_file_name_list))
for j in range(0,len(img_file_name_list)-1):
n=os.path.join("./test/"+names[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_test.append(img)
Y_test.append(i)
X_train=np.array(X_train)
X_test=np.array(X_test)
y_train = to_categorical(Y_train)
y_test = to_categorical(Y_test)
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, Input
from keras.models import Model, Sequential
from keras.utils.np_utils import to_categorical
from keras import optimizers
from tensorflow.keras.callbacks import ReduceLROnPlateau
from keras.callbacks import EarlyStopping
model = Sequential()
model.add(Conv2D(input_shape=(64, 64, 3), filters=32,kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation('sigmoid'))
model.add(Dense(24))
model.add(Activation('softmax'))
reduce_lr = ReduceLROnPlateau(monitor='val_loss',\
factor = 0.5,\
patience = 2,\
min_lr = 1e-08)
es = EarlyStopping(monitor='val_loss', patience=3, verbose=0, mode='min')
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(X_train, y_train,batch_size=32, epochs=50, verbose=1,\
validation_data=(X_test, y_test),\
callbacks = [reduce_lr, es])
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
VGG16による転移学習
転移学習により、VGG16の15層までの特徴抽出部分の重みづけを固定し、16層以降を自分のモデルで学習させます。
from keras.applications.vgg16 import VGG16
input_tensor = Input(shape=(64, 64, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dense(24, activation='softmax'))
reduce_lr = ReduceLROnPlateau(monitor='val_loss',\
factor = 0.5,\
patience = 2,\
min_lr = 1e-08)
es = EarlyStopping(monitor='val_loss', patience=3, verbose=0, mode='min')
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
history = model.fit(X_train, y_train,batch_size=32, epochs=50, verbose=1,\
validation_data=(X_test, y_test),\
callbacks = [reduce_lr, es])
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
どちらのコードでも共通として、過学習を防ぐためにReduceLROnPlateauモジュールを導入し、評価値(今回はバリデーションデータの損失関数(val_loss))が2エポック間改善されなかった場合、学習率を0.5倍しました。
また、EarlyStoppingモジュールを使用し、3エポック間、評価値が改善されなかった場合、学習を打ち切りました。
結果
実装結果は以下のようになりました。
- 通常の畳み込みニューラルネットワークのモデルで学習を行った場合、50エポック学習した時点での分類精度は約70%でした。
- 水増し作業無しで転移学習を行った場合も同様に約70%の精度に収束しました。
- 水増し作業を行い、転移学習を行ったモデルでは、バリデーションデータの損失関数が早い段階で収束し、28エポック時点で学習が打ち切られました。
精度に関しては約80%まで上がり、24分類にしては悪くない精度になったのではないかと思います。
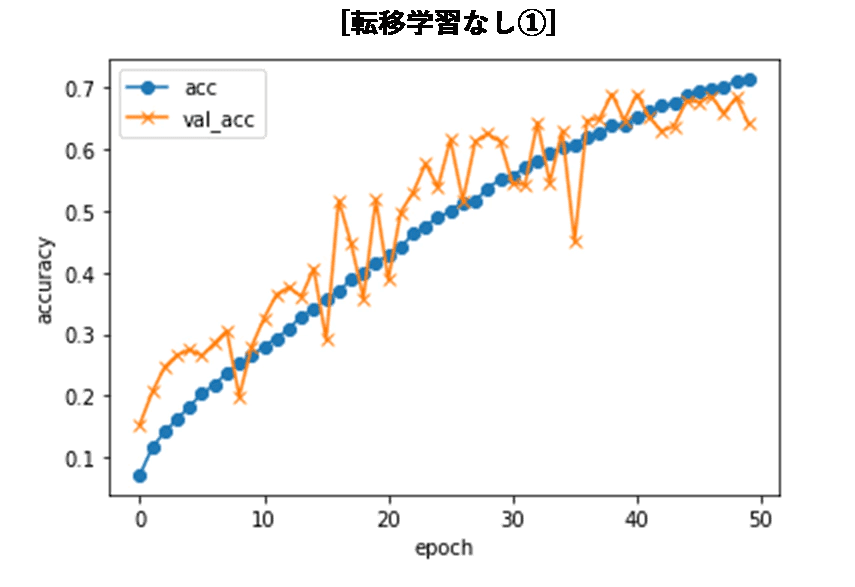

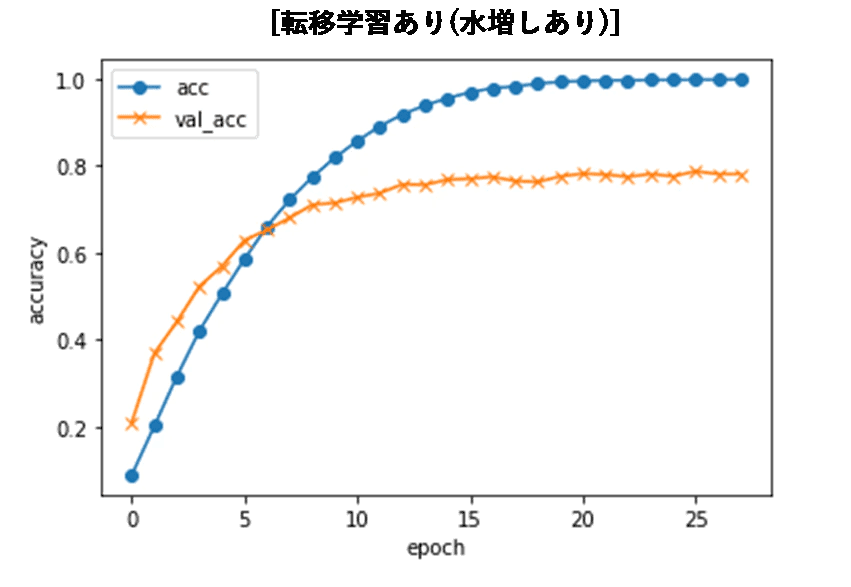
また、上記のように通常の畳み込みニューラルネットワークでは、50エポック時点で学習データの精度も70%ほどだったため、100エポックまで学習を続けた様子も見てみました。結果は以下のようになり、テストデータの分類精度は、50エポックまでの時とあまり変わらず、70%前後に収束していっているのがわかります。

以上より、転移学習を行うことで精度が向上することが確認できたと思います。
また、水増し作業を行わずに転移学習した場合でも、通常のCNNモデルと同等の精度が得られましたが、水増し作業を行うほうがより高い精度を出すことができるという結果も確認できました。
分類例
dic = {0:["AKIRA","EXILE・EXILE THE SECOND"], 1:["ATSUSHI","EXILE"], 2:["TAKAHIRO","EXILE"], 3:["SHOKICHI","EXILE・EXILE THE SECOND"],\
4:["NESMITH","EXILE・EXILE THE SECOND"],5:["TETSUYA","EXILE・EXILE THE SECOND"],6:["NAOTO","EXILE・三代目"],7:["黒木啓司","EXILE・EXILE THE SECOND"],\
8:["橘ケンチ","EXILE・EXILE THE SECOND"], 9:["小林直己","EXILE・三代目"],10:["佐藤大樹","EXILE"], 11:["世界","EXILE"],\
12:["登坂広臣","三代目"], 13:["今市隆二","三代目"], 14:["ELLY","三代目"],15:["山下健二郎","三代目"], 16:["岩田剛典","EXILE・三代目"],\
17:["白濱亜嵐","EXILE・GENERATIONS"], 18:["数原龍友","GENERATIONS"],19:["片寄涼太","GENERATIONS"], 20:["小森隼","GENERATIONS"],\
21:["中務裕太","GENERATIONS"], 22:["佐野玲於","GENERATIONS"], 23:["関口メンディー","EXILE・GENERATIONS"]}
image = cv2.imread("./predict/ファイル名")
b,g,r = cv2.split(image)
img = cv2.merge([r,g,b])
img= np.expand_dims(img,axis=0)
def detect(img):
plt.imshow(img)
plt.show()
name = np.argmax(model.predict(img))
print(dic[name][0]+"("+dic[name][1]+")")
detect(img)
以上のコードにより何枚か分類すると

全体的にうまく分類できていたようです。
※著作権の関係で、似顔絵イラストを使用しています。
ただ、ATSUSHIさんに関しては、「サングラスATSUSHI」は100%分類できているのですが、下のように「眼鏡ATSUSHI」や「サングラス無しATSUSHI」はうまく分類できていないようでした。


SHOKICHI(EXILE・EXILE THE SECOND)
理由として、メディアでもサングラスでの出演が多いため、画像収集の際にATSUSHIさんの画像が「サングラスATSUSHI」に偏ってしまったことが考えられます。
また、他のメンバーもサングラスを着用しているとATSUSHIさんに間違われてしまうことがありました。
最後に
機械学習の学習を始めて1か月ほどで、初めて実装を行いましたが、自分で手を動かしてみることで、CNNや転移学習の仕組みを理解し直すとてもいい機会になりました。
今回は転移学習の学習済みモデルとしてVGG16を使用しましたが、近年では、どの学習済みモデルを使うことが最適か判断できる手法も明らかになってきています。それを利用して最適な学習済みモデルで転移学習を行えば、今回の結果以上に良い精度が出ることも期待できます。
今後はこのようなモデルの選択といった分野にも精通できればと思います。
参考

