
こんにちは。アイデミーの松岡です。
プログラミング初心者で、現在勉強中です。
突然ですが、皆さんは車はお好きでしょうか?
私は特に車好きというわけではなく、正直に言うと「乗れればいいかな」と思っているレベルで、あまり知識はありません。
街を歩いていると、時々かっこいい車を目にすることがあります。
しかし、車の名前を全然知らないので、調べたくても調べることができません。
そこで、今回はCNNを使用して自動車の車種を判別するAIを作りたいと思います。
⏩CNNとは?
目次
使用するデータ
データはKaggleにあるトヨタ車の画像を使用します。
https://www.kaggle.com/occultainsights/toyota-cars-over-20k-labeled-images
このデータには38種類の車の画像が保存されています。
まず実際にダウンロードして、画像を確認しました。

こうして見てみると、車内の画像もあることがわかります。
今回作りたいのは、外から見たときの車を判別するモデルなので、車内の画像は取り除かなければいけません。
しかし、1枚1枚手作業で行うと、かなり面倒ですね。ざっと2万枚ほどありそうです。
そのため、機械学習を使用して車内の画像を取り除くことにしました。
画像分別機にもCNNを使用します。
実行環境
Google Colaboratory
Python 3.7.2
Keras 2.4.3
Numpy 1.19.5
TensorFow 2.4.1
車内判別器の作成
車内画像分別器を作るために車内の画像が必要です。そこでKaggleにある車内のデータセットを使います。
https://www.kaggle.com/igorkovr/car-interiors

こちらのデータ数は70とかなり少ないです。
そこで、アフィン変換などを行うことで、データを水増ししてからCNNを実装します。
CNNのネットワーク構造は、Aidemy Magazineの記事を参考に作成しました。
以下がCNNのプログラムになります。
#車内判別
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
import numpy as np
import keras
import matplotlib.pyplot as plt
classes = ['車内','車']
num_classes = len(classes)
image_size = 64
#メインの関数を定義する
def main():
X_train,X_test,y_train,y_test = np.load("./car-hanbetu.npy", allow_pickle=True)
#画像ファイルの正規化
X_train = X_train.astype('float') / 255
X_test = X_test.astype('float') / 255
y_train = np_utils.to_categorical(y_train,num_classes)
y_test = np_utils.to_categorical(y_test,num_classes)
model = model_train(X_train,y_train,X_test,y_test)
model_eval(model,X_test,y_test)
def model_train(X_train,y_train,X_test,y_test):
model = Sequential()
model.add(Conv2D(32,(3,3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation('softmax'))
#最適化の手法
opt = keras.optimizers.RMSprop(lr=0.00005,decay=1e-6)
#モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=opt,metrics=['accuracy'])
#historyに['val_loss', 'val_acc', 'loss', 'acc']を保存
history = model.fit(X_train, y_train, batch_size=32,epochs=40,validation_data=(X_test,y_test))
#モデルの保存
model.save("./car-hanbetu.h5")
#学習曲線の可視化
graph_general(history)
return model
def model_eval(model,X_test,y_test):
scores = model.evaluate(X_test,y_test,verbose=1)
print('Test Loss: ', scores[0])
print('Test Accuracy: ', scores[1])
def graph_general(history):
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train_acc', 'Test_acc'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train_loss', 'Test_loss'], loc='upper left')
plt.show()
if __name__ == '__main__':
main()こちらが学習曲線になります。
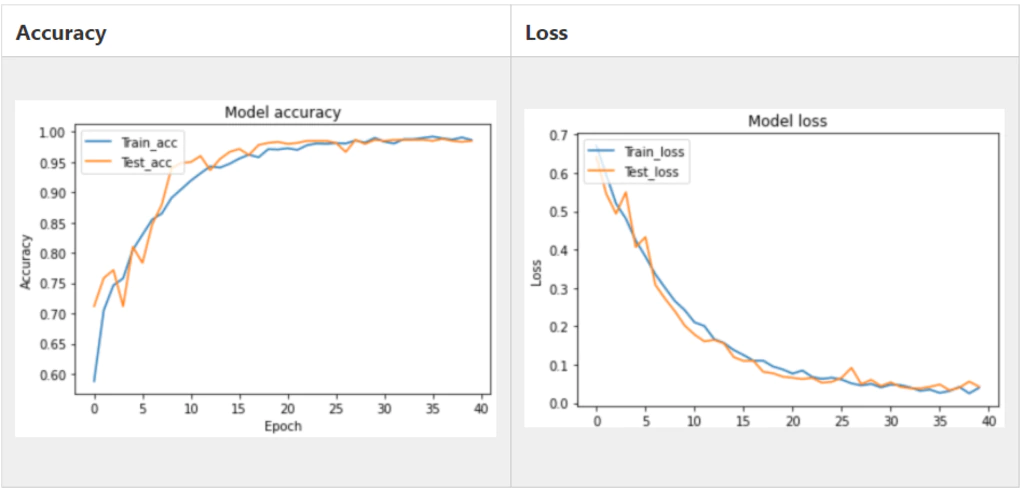
Test Accuracyが0.990とかなり高い値であり、十分判別できるモデルであることが確認できます。
では作成したモデルを使用して、画像を判別し、車内画像であれば削除するプログラムを実装します。
#車内判別
from keras.models import load_model
import matplotlib.pyplot as plt
from PIL import Image
import os,glob
import numpy as np
from sklearn import model_selection
img_size = 64
model_param = "./car-hanbetu.h5"
classes = ['4runner','camry','corolla','highlander','prius','rav4','sienna','tacoma','yaris']
model = load_model(model_param)
#それぞれのファイルごとにループさせる
for index, class_ in enumerate(classes):
photos_dir = "./車/" + class_
#jpg形式の画像データを保存
files = glob.glob(photos_dir + '/*.jpg')
for i, file in enumerate(files):
img = Image.open(file)
img = img.convert('RGB')
#画像データを64 x 64に変換
img = img.resize((img_size, img_size))
# 画像データをnumpy配列に変換
img = np.asarray(img)
img = img / 255.0
pred = model.predict(np.array([img]))
print(round(pred[0][0] / 1.0, 3) *100 , "%", round(pred[0][1] / 1.0, 3) *100 , "%" )
ans = np.argmax(pred, axis=1)
#車外か車内かを判別
if ans == 0:
print(">>> 車")
elif ans == 1:
print(">>> 車内なので削除")
os.remove(file)実際に以下の2枚の画像を入れてみましょう。

実行結果は以下になります。
99.7 % 0.3 %
>>> 車
6.5 % 93.5 %
>>> 車内なので削除ちゃんと判別できていますね。
このコードを実行することで、元データから車内画像を削除することができました。
では、データを整えたので車種を判別するAIを実装していきます。
車種を判別するCNNの実装
ラベル2個
まずはラベルを2個にして行います。
使用するのは「4runner」と「prius」です。
データ数は「4runner」が718、「prius」が838となっています。
CNNのネットワーク構造については、上記で使用したものと変わりませんので、コードは省略します。
こちらが学習曲線になります。
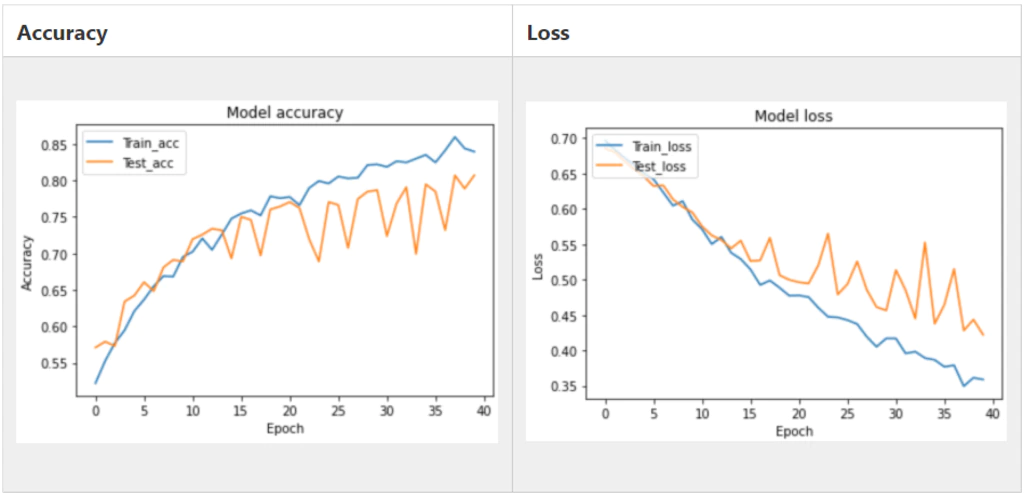
あまり精度がよくないですね。
やはり車の形を見極めるにはもう少しデータが必要なようです。
そこで、アフィン変換などを行ってデータを水増しします。
こちらが水増しを行ったデータになります。

データ数は「4runner」が13623、「prius」が15827になりました。
このデータを使用してCNNを行った結果が以下になります。
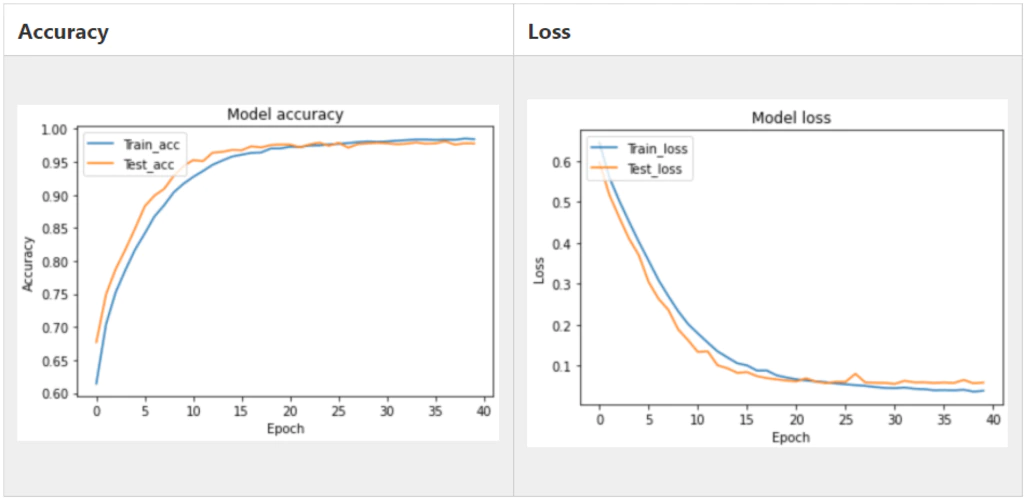
だいぶ改善されましたね!
Test Accuracyが0.978でした。
ここまで精度が高ければ問題なさそうです。
しかし、これは2車種の分類です。
日本車だけでも多くの車種があるので、2種類に分類するモデルなどはあまり実用的ではないですね。
そこで、これからラベルをさらに増やします。
ラベル9個
ラベルは先ほど使用した「4runner」と「prius」に、
「camry」「corolla」「highlander」「rav4」「sienna」「tacoma」「yaris」
を追加した合計9個です。
ネットワーク構造は、最後の全結合層の出力を9に変更しただけです。
def model_train(X_train,y_train,X_test,y_test):
model = Sequential()
model.add(Conv2D(32,(3,3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(9))
model.add(Activation('softmax'))これが実際に行った結果です。
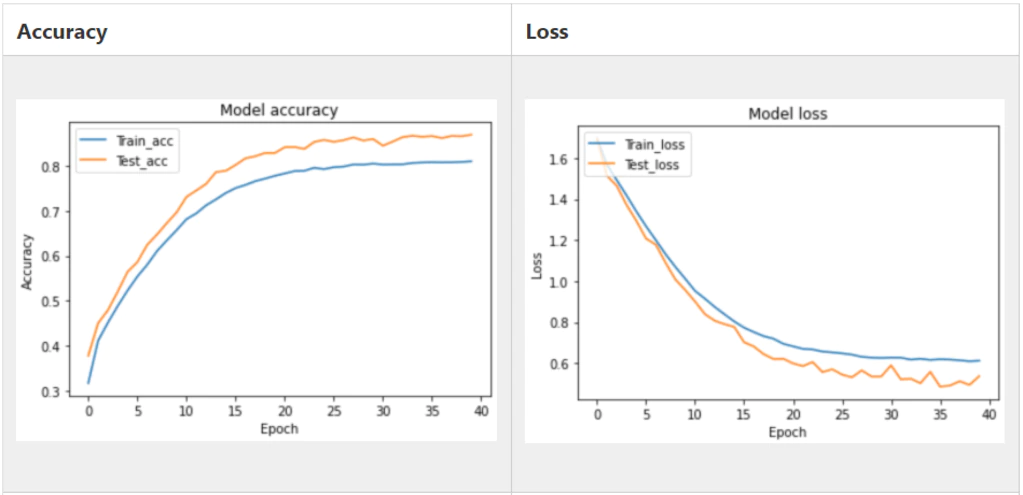
Test Accuracyは0.869でした。やはり、2個で行った時よりかなり精度が落ちてしまいました。
理由としては、車にはバージョンやクラスがあり、同じラベルに所属していてもかなり形が異なるものがあります。以下は今回使用した元データにある「corolla」の画像2枚です。

同じラベルでも形が全然違いますね。
これが精度を下げる原因と考えられます。
アンサンブル学習
これまでCNNを作成してきて、この精度で終了するのは少し悔しいのでもう少し粘ってみます。使用する手法はEnd-to-Endなアンサンブル学習です。
⏩アンサンブル学習とは?
こちらのサイトが参考になります。
上記サイトを参考に、コードを作成しました。
# 確率の平均を取るアンサンブル(ソフトアンサンブル)
def ensembling_soft(models, X):
preds_sum = None
for model in models:
if preds_sum is None:
preds_sum = model.predict(X)
else:
preds_sum += model.predict(X)
probs = preds_sum / len(models)
return np.argmax(probs, axis=-1)
# 多数決のアンサンブル(ハードアンサンブル)
def ensembling_hard(models, X):
pred_labels = np.zeros((X.shape[0], len(models)))
for i, model in enumerate(models):
pred_labels[:, i] = np.argmax(model.predict(X), axis=-1)
return np.ravel(mode(pred_labels, axis=1)[0])ソフトアンサンブル
以下がソフトアンサンブルの結果になります。
| 分類器の数 | 単体の精度 | アンサンブルの精度 |
| 1 | 0.875 | 0.875 |
| 2 | 0.872 | 0.880 |
| 3 | 0.871 | 0.894 |
| 4 | 0.880 | 0.905 |
| 5 | 0.878 | 0.906 |
分類器が増えるごとに精度が上昇していることがわかります。
分類器5個ではTest Accuracyが0.906まで上がりました。
また、アンサンブル学習で重要になるのは相関係数です。相関係数が0.95以上あるようなモデル同士で多数決をとっても、ほとんど同じ結果しか返さないため意味がありません。
相関係数は以下のようになっています。
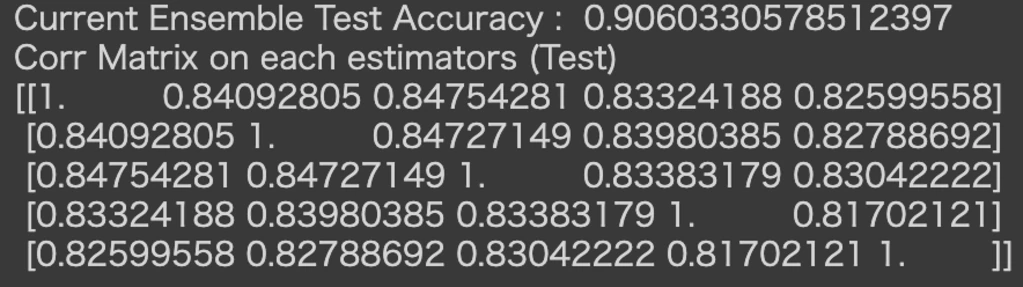
相関係数は0.81~0.85と低いので、かなり効率の良い多数決が行われていると確認できます。
ハードアンサンブル
以下がハードアンサンブルの結果になります。
| 分類器の数 | 単体の精度 | アンサンブルの精度 |
| 1 | 0.870 | 0.870 |
| 2 | 0.879 | 0.876 |
| 3 | 0.873 | 0.887 |
| 4 | 0.880 | 0.895 |
| 5 | 0.875 | 0.901 |
こちらでも分類器が増えるごとに精度が上昇しており、5個では0.901になりました。
相関係数は以下のようになっています。
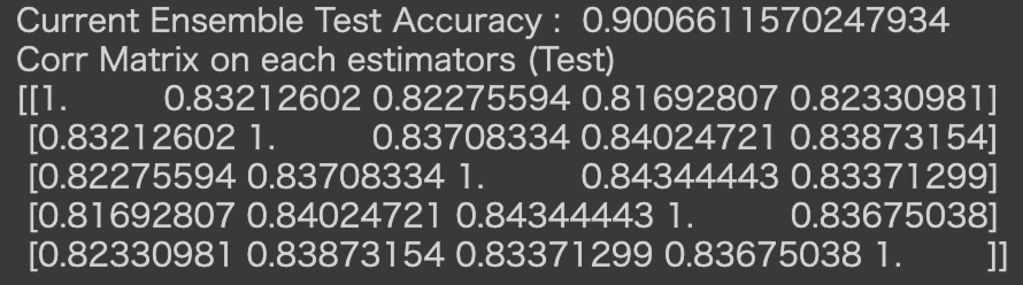
相関係数は0.81~0.85と低いので、かなり効率の良い多数決が行われていることが確認できます。
どちらの結果も、Test Accuracyが0.9より高く、普通のCNNに比べて精度を向上させることができました。
まとめ
今回は、CNNを使用して車種を見極めるAIを作成しました。
精度はラベル9個で0.869とあまり高くありませんでしたが、アンサンブル学習を使用して0.9まで上昇させることができました。
さらに精度を上げたい場合は、元データのラベルをさらに分けることが有効だと考えます。
車種ごとではなく、車種のバージョンごとにデータを作成すれば、もっと高い精度を出すことができると考えます。
今回ご紹介した画像認識の仕組みは、Python専門オンラインスクールAidemy Premium Planの「AIアプリ開発講座」で学習が可能です。
参考文献
https://www.kaggle.com/occultainsights/toyota-cars-over-20k-labeled-images
https://www.kaggle.com/igorkovr/car-interiors
https://premium.aidemy.net/magazine/entry/2019/04/12/114812
https://qiita.com/koshian2/items/d569cd71b0e082111962
https://jp.mathworks.com/discovery/convolutional-neural-network.html
https://deepage.net/deep_learning/2016/11/07/convolutional_neural_network.html
https://products.sint.co.jp/aisia/blog/vol1-16
▼この記事はQiitaでも公開しています。
https://qiita.com/analog12/private/9ae848fa3c37b0280b33
