

はじめまして。Aidemy研修生のこんどうです。 本屋のビジネス書コーナーに行くとこんなことを思います。
「売れてるビジネス書のタイトルを分析して最強のタイトルを考えれば たとえ中身がなんであろうと爆発的に売れるのではないか」
そんな妄想を背景として本記事では 「自然言語処理を用いたビジネス書タイトルの分析」 について書いていきたいと思います。
目次
全体の流れ
ランキングサイトからスクレイピングでデータ収集 ↓ 形態素解析で品詞分解 ↓ 単語ごとに出現回数を表示して分析
環境
- Python 3.6.4
- jupyter notebook 4.4.0
- windows 10
スクレイピング
東洋経済ONLINEのサイトでAmazonのビジネス書売り上げランキングが 毎週1位~200位まで発表されているので 今回はそれをスクレイピングで自動収集していきます toyokeizai.net

本のタイトルの取得と同時に順位に応じてポイントをつけていきます データについて
import pandas as pd
import urllib.request
from bs4 import BeautifulSoup
import json
import time
import numpy as np
#スクレイピングしてタイトルとポイントをjson形式で出力
#リンク一覧ページからランキングサイトのリンクを取得
link_list=[]
for i in range(1,11):
url_ranking_list_root="https://toyokeizai.net/category/weeklyranking"
page_url="?page="+str(i)+"&per_page=15"
url_ranking_list=url_ranking_list_root+page_url
html=urllib.request.urlopen(url_ranking_list)
soup=BeautifulSoup(html,"lxml")
link_html_list=soup.find_all("a",class_="link-box")
for link_html in link_html_list:
link_list.append(link_html.get("href"))
time.sleep(1)
link_list=list(set(link_list))
#辞書作成
dict={}
for n in range(0,len(link_list)):
for page_num in range(2,6):
root_url="https://toyokeizai.net"
page_url="?page="+str(page_num)
url=root_url+link_list[n]+page_url
html=urllib.request.urlopen(url)
soup=BeautifulSoup(html,"lxml")
title_list=soup.find("tbody").find_all("a")
for i in range(len(title_list)):
if title_list[i].text not in dict:
dict[title_list[i].text]=200-(i+50*(page_num-2))
else:
dict[title_list[i].text]+=200-(i+50*(page_num-2))
time.sleep(1)
#json形式で出力
with open("book_data.json","w",encoding="utf-8") as f:
json.dump(dict,f,indent=4,ensure_ascii=False)形態素解析で品詞分解
スクレイピングで収集したタイトルを形態素解析していきます 形態素解析とは… 文章を意味のある単語ごとに分解する技術です

今回は本のタイトルを形態素解析したあと それぞれの単語の出現回数をカウントしていきます 用いるライブラリ:janome
from janome.tokenizer import Tokenizer
import numpy as np
import pandas as pd
with open("book_data.json","r",encoding="utf-8") as f:
dict=json.load(f)
title_list=list(dict.keys())
point_list=np.array(list(dict.values()))
title_wakati=[]
for i in range(len(title_list)):
#正規表現で不要頻出語を削除
title=title_list[i]
title=re.sub("新書","",title)
title=re.sub("単行本","",title)
title=re.sub("雑誌","",title)
title=re.sub("文庫","",title)
title=re.sub("[。!-/:-@[-`{-~]","",title)
t=Tokenizer()
tokens = t.tokenize(title)
for token in tokens:
partOfSpeech = token.part_of_speech.split(",")[0]
surface = token.surface
#1語の単語を削除して名詞と動詞のみを取り出し
if len(surface) > 1:
if partOfSpeech == "名詞":
title_wakati.append(surface)
if partOfSpeech == "動詞":
title_wakati.append(surface)
#単語数をカウント
d_count=collections.Counter(title_wakati)
d_count=d_count.most_common
#DataFrame化
word_dct={"単語":[],
"出現回数":[]}
for i in d_count:
word_dct["単語"].append(i[0])
word_dct["出現回数"].append(i[1])
df=pd.DataFrame(word_dct)
df=df_top.sort_values("出現回数",ascending=False)
df.reset_index(drop=True,inplace=True)
df.to_csv("book_data.csv")
結果
ビジネス書に出てくる単語ランキング
出力結果

上位一部だけ抜粋 「会社」「仕事」「経済」 などの一般的によく使われる単語から
「ビジネス」「教科書」「最強」「リーダー」「戦略」 などのビジネス書にありがちな単語も多く見られます
売れ行きで重みづけしたランキング
ここで先ほど集計したポイントで単語を重みづけしてみます
つまり売れている本に出ている単語をより重要な単語として扱うということです
with open("book_data.json","r",encoding="utf-8") as f:
dict=json.load(f)
#ポイントに√をかける
title_list=list(dict.keys())
point_list=np.array(list(dict.values()))
point_list_root=np.sqrt(np.abs(point_list))
#ポイントに応じて単語を重みづけ
title_list_ex=[]
for i in range(len(point_list_root)):
title_list_ex.append(title_list[i]*int(point_list_root[i]))
title_wakati=[]
for i in range(len(title_list_ex)):
#正規表現で不要頻出語を削除
title=title_list_ex[i]
title=re.sub("新書","",title)
title=re.sub("単行本","",title)
title=re.sub("雑誌","",title)
title=re.sub("文庫","",title)
title=re.sub("[。!-/:-@[-`{-~]","",title)
t=Tokenizer()
tokens = t.tokenize(title)
for token in tokens:
partOfSpeech = token.part_of_speech.split(",")[0]
surface = token.surface
#1語の単語を削除して名詞と動詞のみを取り出し
if len(surface) > 1:
if partOfSpeech == "名詞":
title_wakati.append(surface)
if partOfSpeech == "動詞":
title_wakati.append(surface)
#単語数をカウント
d_count=collections.Counter(title_wakati)
d_count=d_count.most_common()
#DataFrame化
word_dct={"単語":[],
"出現頻度":[]}
for i in d_count:
word_dct["単語"].append(i[0])
word_dct["出現頻度"].append(i[1])
df_ex=pd.DataFrame(word_dct)
df_ex=df_ex.sort_values("出現頻度",ascending=False)
df_ex.reset_index(drop=True,inplace=True)
df_ex.to_csv("book_data_ex.csv")結果

あまり変わりませんね….
上位と下位の単語出現頻度の比較
売上で重みづけしてもあまり順位が変わらなくてやや焦ってきましたが
じゃあ売上の上位と下位で使われている単語に違いはないのか?
と思ったので売れ行き上位10%と下位10%の本のタイトルを比較することにしました(先ほど扱ったポイントの上位10%と下位10%を抽出)

ご覧のとおり全然変わらないです…. 「ビジネス書のタイトルどれも同じなのではないか」 という結論が見えてきました。
売上に貢献している単語は?
そこで続いては 売上ポイントに寄与している単語はなにかを調べてみることにします 最頻出単語の上位400個(上位10%)を取り出して、各タイトルについて 含まれていれば1、含まれていなければ0をつけてカテゴリー化します ダミー変数については以下のリンクを参考にしてください xica.net
出力結果はこのようなデータフレームになります

scikit-learnのライブラリfeature_selectionを用いて
売上ポイントに最も寄与した単語を指定した個数(今回は20個)だけ取り出します
変数選択手法について aotamasaki.hatenablog.com f
eature_selectionについて qiita.com
変数選択手法のなかで今回はFilter Methodの分散分析とWrapper MethodのRFEを使用しています 詳しくはリンクを参照していただきたいのですが ・分散分析:説明変数のどれを選ぶかを変えることで予測値がどれくらい変わるかを計算して重要変数を見つける手法 ・Wrapper Method:変数を選んだらモデルを作成して予測値を計算することで重要変数を見つける手法 Filter Method
出力結果がこちらです

「NewsPicks」「Book」「業界」 のスコアが高いのでこれらの単語が入っているとポイントが上がる傾向があるようです Wrapper Method
出力結果

大方は一致していますね RFEのほうでは重回帰分析モデルをいちいち作成してるのでこっちのほうが正確な気もします これらの結果から売上と相関の強い単語だけを集めたビジネス書タイトルを考えてみました 「ハーバード式 本質的な考え方の授業」 「生き方を変える行動の科学(NewsPicks)」 なんか普通にありそうなタイトルですね…
結果の分析と反省
・ビジネス書のタイトルによく出てくる単語は相当偏ってそうです。直感的には「似たようなタイトル多いなぁ」と感じますが定量的に見てみると明らかです
・売上の上位も下位もタイトルに使われている単語は大方共通でした。
ここに大きな差が出てくれると面白かったのですが… ベストセラーに共通の単語は見つかりませんでしたが、 売上と相関のある単語が見つかったのは今回1番の収穫でした
もちろん相関関係と因果関係は別ですが… 今回はランキングの1位~200位までしか取れなかったので単語レベルでも似たようなものしか出てこなかったのかと思います もっと幅広いビジネス書のタイトルと売上を集計できればよりおもしろい結果が出そうです データ収集の重要性と難しさを改めて感じますね
おまけ)ビジネス書のトレンド
先ほどは売れ行き順にクラスを分割しましたが 時系列順に分割してみたらおもしろいことが分かるのではないか つまり ビジネス書のタイトルのトレンドからその時々のビジネスパーソンの関心事もわかるのではないか ということです 単語を抽出する操作は大体同じなのでコードは割愛します 期間は半年をひと区切りとして計5つの期間に分けました
ブロックチェーンとビットコイン
まず近年注目の集まっている単語「ブロックチェーン」「ビットコイン」に注目してみました 2つの単語が含まれているタイトル数を各区間で週計してグラフにしたもの(上段)と Googleトレンドで調べた2つの単語の日本での検索数(下段)をグラフにしました。
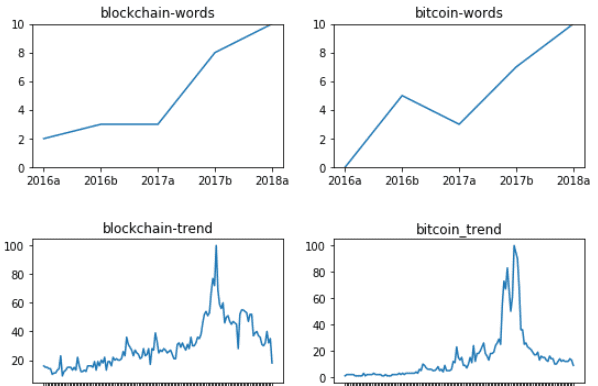
ビジネス書のトレンドも世間のトレンドと同時に上がっていますが、 世間ではすぐに冷めた関心がビジネス書ではより大きくなっているところが興味深いです。
TOYOTAとGoogle
「トヨタ」と「Google」の出現回数の推移も調べてみました。
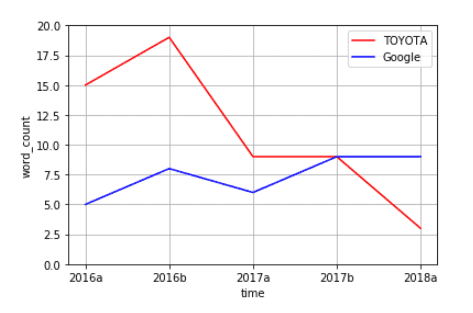
2年前まで20近い出現数だった「トヨタ」は近年数を落とし、 「Google」が数を伸ばしてきています。経営システムのトレンドがトヨタ流からシリコンバレー流に変化していることがビジネス書のタイトルからも定量的に分かるというのはひとつおもしろい発見でした。
おわりに
直感的に感じていることを定量的に表すというのは新しいことを発見する良い手がかりになると思いますのでぜひ色々な場面で挑戦してみてほしいと思います この記事が少しでもその助けになれれば幸いです
