
はじめまして、研修生ののっぽです。機械学習の勉強を始めてまだ二ヶ月の未熟者ですが、今回は機械学習を用いた簡単なプログラムの実装をしてみようと思います。
突然ですが、皆さんはTwitterを使用したことがありますか?あるいは他のSNSを用いたことはありますか?
Twitter等のSNSでは大きなアカウントであればあるほどログの流れが早く、後から見返すのが大変です。
そこで、pythonを用いて過去のツイートを大量に取得し過去にどのようなことがツイートされていたのかを大まかに知るプログラムを作ってみます。
さて、タイトルにもあるトピックモデルとは一体どういう意味なのでしょうか。
トピックモデルとは簡単に言うと「全ての文章には幾つかの話題があり、文章の中身はその話題の何れかから作られている」というモデルのことです。
そしてトピックモデルを生成するとは、各文章中の単語を生成元の話題に対してグループに分け、それらの単語がどれだけの確率でどの話題から生成されたのかを推定することになります。 詳しい解説はAidemyの講座にお任せすることとして、早速ツイートを取得してトピックモデルを生成してみましょう。
ツイートを取得する
ツイートの取得に当たって以下の記事を参考にさせていただきました。 qiita.com TwitterにはAPI制限というものが存在し、タイムラインからのツイートの取得は200(ツイート/回)×15(回) = 3000ツイートが限界です。
そのため、API制限に掛かった場合はプログラムを一時的に停止させる必要が有ります。以下に示したプログラムでは一回ツイートを取得するごとに1分停止することで結果的に制限にかからないようにしています。 また、ツイートを遡るために最後に取得した最も古いツイートのIDを一時的に保持しています。
(上記のコードはプログラムの一部です。実際にはツイート取得数を増やすために、複数アカウントのタイムラインからツイートを取得しています) 以上のプログラムで20000×アカウント数のツイートが取得できることになります。 しかし、そのままではトピックモデルを形成することはできません。そこで得られたツイート群に対して形態素解析を行い必要な単語のみを抽出します。
ツイートを整形する
ツイートの整形(形態素解析)にはMeCabというライブラリを用います。 以下のコードではparserという関数で一つのツイートの形態素解析を、analyzerという関数でリスト内のツイート全てにparser関数をかけています。
さて、それでは生成されたトピックモデルをcsvファイルに保存し確認してみましょう。
LDAとは
結果に移動する前にLDAについて簡単な説明をします。 LDAとはトピックモデルの中でもベイズ推論の考えを用いて文章の集合から各トピックや単語がどのから生成されたかについての分布を計算するモデルです。 以下にすこし詳しい説明を書きます。
n個の単語の集合をW、語彙(つまり単語の種類)の集合をV、文書集合をDとします。 この時、文書集合D中のある文書dは単語wの集合として表されます。また文書集合DにはK個のトピックφによって構成されるトピック集合Φが存在しトピックφは語彙vの異なる比率によって構成されています。 また文書dそのものはトピックを幾つか含んでいるのでトピックφが文書dを占める比率をθとおきます。
最後に単語がどのトピックに属するかを示す変数であるトピック割り当てZを設定します。 トピックの総数が決まっている時、単語w及びトピック割り当てはカテゴリ分布(ベルヌーイ分布を多次元に拡張したもの)によって生成されます。
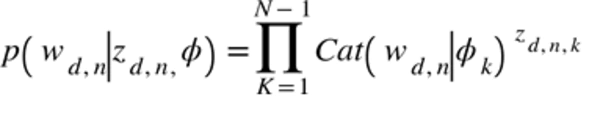
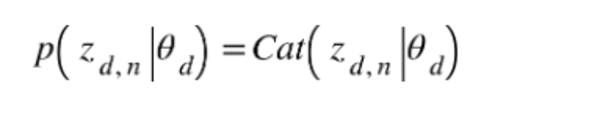
つまり、単語wの生成される確率はトピック集合Φとそれらの割り当てzに依存し、割り当てzの生成される確率は文書dに含まれるトピックの比率θに依存するということです。 この時、トピック比率及びトピックφがそれぞれディリクレ分布から生成されていると仮定すると、結局全体の同時分布は以下の式で表されます。
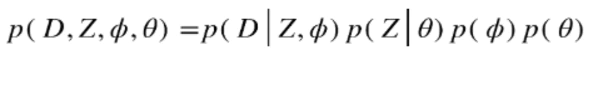
(ただし、上式において集合の確率は各要素の確率の積で表されるとします)
今求めたいのはp(D,Z,Φ,Θ)に対してp(D)が与えられた際の事後分布
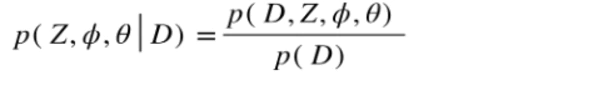 です。
です。
ここで変分推論を適用し先ほど求めた式を用い、潜在変数Zと他のパラメータ分解を仮定することでLDAにおける解析的な更新式が求まります。
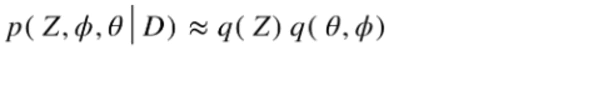
この更新式はΘ及びΦのディリクレ分布のハイパーパラメータα及びβから求まります。
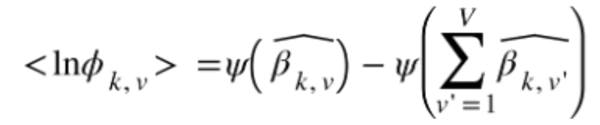
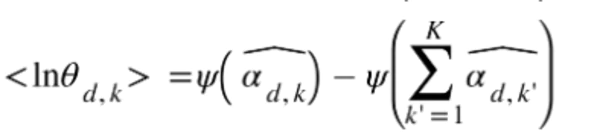
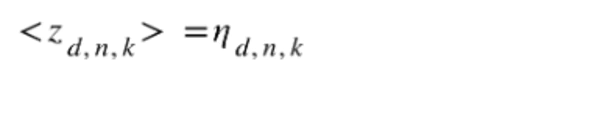
~ただし、変数はそれぞれ以下のように設定しました~
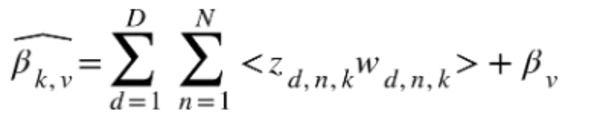
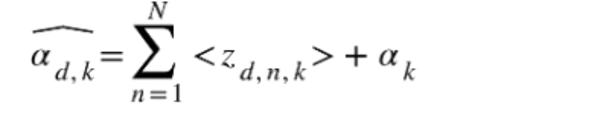
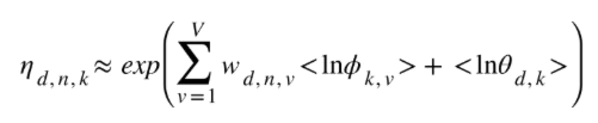
ただし 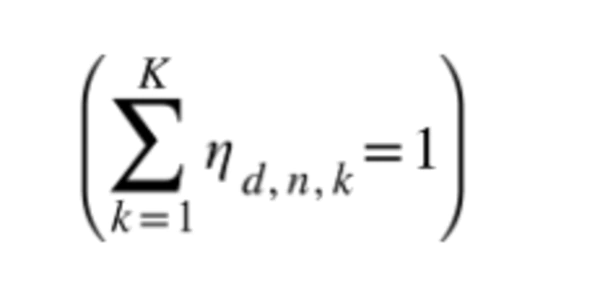
~これらの更新式において崩壊型ギブスサンプリングというpからパラメータΘ,Φを周辺化除去しzの条件付き分布を求めるサンプリング方法によってαとβの更新が可能になります。 LDAは確率モデルであり拡張性が高いため、広く使われています。
結果
以下の画像は作成したTwitterの4つのサンプルアカウント(フォローに法則性のないアカウント,アニメ・ドラマ・ゲーム等の内容をつぶやくユーザーの多いアカウント,数学・物理・情報等の学問についてつぶやくユーザーが多いアカウント,僕自身のアカウント)から生成されたトピックを30個分取り出したものになります。 …可もなく不可もなくといったところでしょうか

これらのトピックのようにうまく単語をまとめられたものもありますが、
![]()
![]()
![]()
中にはとんちんかんなトピックもあります。 Twitterでは多くの著者と多くの話題が混在しているためうまくモデルを推定するのが難しいのかもしれません。
そこでモデルのパラメータであるトピック数と辞書の作成に用いたパラメータである単語の最低出現数(no_below)についてパラメータの適解を探索します。 モデルの評価に用いるのはperplexityと言う指標でトピックからある単語が生成される確率の逆数によって表されます。
つまり、この数値が小さければ小さいほどモデルの予測性能は向上するのでうまく構築出来たと言うことになります。
はじめにトピック数及びに単語の最低出現数ついて大まかに探索することで大体のperplexityの傾向を探ったところ、今回はトピック数はだいたい200程度、最低出現数はだいたい18程度で極小値に収束することがわかりました。 そこでさらに細かく全探索していきます。
全探索をしたところ、トピック数219, 最低単語出現数19でperplexityの極小値25.48が得られました。 このパラメータを用いてもう一度トピックモデルを構築したところ以下のようになりました。

ちょっとは改善されているのでしょうか…?
新しく取得したツイートのトピック
では、取得したツイートのトピックモデルを用いて新たに取得したツイートがどのトピックに属しているのかを確認してみましょう。 先ほど用いたアニメ、ドラマ等のアカウントをフォローしているサンプルアカウントのタイムラインから以下のツイートが得られました。
[映画ニュース] 松坂桃李、役所広司の“魂”が込められた「孤狼の血」キーアイテムを継承! https://t.co/4GRx9zMsfO pic.twitter.com/pnS86bM81v
— 映画.com (@eigacom) 2018年4月25日
「江口洋介」さんが関わっていることがわかりますね。
最後に
今回はpythonを用いて身近な題材について機械学習のプログラムを実装してみました。機械学習というとハードルが高く見えるかもしれませんが、ライブラリが充実しているので簡単なものであれば誰にでも作れてしまうものです。
とはいえ、精度や学習速度など奥が深い分野であることもまた事実です。僕もトピック数の決定や評価法などまだまだ改良点があるのでまた挑戦してみようと思います。 ご清覧ありがとうございました
またLDAの説明に関して以下の本を参考にさせていただきました。より詳しく機械学習について知りたい方にとてもおすすめの本です。

機械学習スタートアップシリーズ ベイズ推論による機械学習入門 (KS情報科学専門書)
- 作者: 須山敦志,杉山将
- 出版社/メーカー: 講談社
