
はじめまして、protonです。 数カ月前からやっと機械学習関係の勉強を始めましたが、思った以上に色々出来て面白くなってきたところです。 機械学習にはscikit-learn等の様々な便利なオープンソースライブラリがあり、それらを用いることでかなり簡単に実装することができます。 今回はあえて、scikit-learn等を使わずに独立成分分析(ICA)というものを実装し、音声データの分離をしてみました。
独立成分分析(ICA)とは?
様々な人が話している中でも、自分が話している相手の会話は聞き取ることができるという現象は(おそらく)誰でも経験していると思います。 この現象をカクテルパーティ効果といい、人には音源の位置や周波数の差から特定の音を抽出するような機能が備わっています。 この機構を模したアルゴリズムが、独立成分分析(ICA : Independent Component Analysis)です。
独立成分分析のアルゴリズム
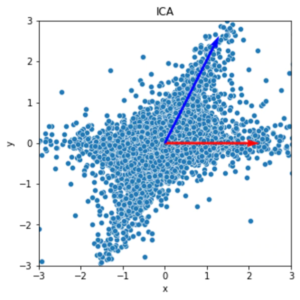
これはある2つの観測データ(2つの音源が別々の割合で混合されたもの)をそれぞれ横軸と縦軸に設定した散布図で、ICAが分離した様子がわかります。(ICA前にデータの分散が大きい方向がなんとなくX字のように2つあるものを、直行するように座標変換してるイメージ。
もっとわかりやすいデータを持ってきても良かったのですが、このぐらいでも分離することができることがわかってもらえると…) これをどのようにしてプログラムで行うかというと、任意の独立な確率変数の和は正規分布に収束するという中心極限定理を利用します。
中心極限定理により、独立な音源よりもそれを足し合わせたデータのほうがより正規分布に近くなる場合が多く、逆に正規分布から離れた分布であれば、独立な音源が足し合わさっていない(と判断できる)ということになります。
どれだけ正規分布に近いかどうかを判断するのに、尖度という統計量があります。尖度は正規分布の時に0、正規分布から乖離するほど0から離れていくので、この尖度が最大になった時が観測データ同士の独立性が最も高くなる時で、元の音源を分離することができます。(ここからわかるように元のデータが正規分布に近いものだと、分離が難しくなります…)
尖度が指標としてなぜ有効なのかや、尖度を最大化させるために繰り返し更新するアルゴリズムについては最後にリンクを貼った本を読んでみてください…
準備
音源分離には様々なパターンがあるらしいですが、基本的には独立した音源の数だけそれぞれ同期したマイクを周囲に適当に設置して、マイクから拾った音を元にそれぞれの音源を抽出します。
実際にマイクをいくつか買ってきて録音するのは音源とは関係ない雑音等も入り、勉強始めたての自分には難しすぎるので、今回はフリー音源を3つ適当な割合で混合したデータから音源を分離することにします。(マイクの位置による時間差は無視して、マイクの位置による音の減衰による差を反映しています。) 扱いやすくするために、soundengine等を使ってwav形式16bit, 44100Hz, モノラルでちょうど10秒の音声データに加工します。
loop1.wav
strings.wav
fanfare.wav
次に、pythonを使って3つの音源を適当な割合で混合したデータを3つ作ります。 (コードの通りmix_1,2,3はそれぞれloop1.wav, strings.wav, fanfare.wavを(0.6, 0.3, 0.1), (0.3, 0.2, 0.5), (0.1, 0.5, 0.4)の割合で混合したものです)
import numpy as np
import scipy.io.wavfile as wf
rate1, data1 = wf.read('loop1.wav')
rate2, data2 = wf.read('strings.wav')
rate3, data3 = wf.read('fanfare.wav')
if rate1 != rate2 or rate2 != rate3:
raise ValueError('Sampling_rate_Error')
mix_1 = data1 * 0.6 + data2 * 0.3 + data3 * 0.1
mix_2 = data1 * 0.3 + data2 * 0.2 + data3 * 0.5
mix_3 = data1 * 0.1 + data2 * 0.5 + data3 * 0.4
y = [mix_1, mix_2, mix_3]
y = [(y_i * 32767 / max(np.absolute(y_i))).astype(np.int16) for y_i in np.asarray(y)]
wf.write('mix_1.wav', rate1, y[0])
wf.write('mix_2.wav', rate2, y[1])
wf.write('mix_3.wav', rate3, y[2])mix_1.wav
mix_2.wav
mix_3.wav
なかなかひどいものができてしまいましたが、どれか一つの音に集中しようとしてみると結構難しいと思います。(できる人もいると思うけど) こんなぐちゃぐちゃになったデータから元のデータを抽出します。
音源分離
分離すべきデータができたので、独立成分分析(ICA)関係の処理についてまとめた ica.pyを作ります。(analyzeのアルゴリズムについては最後の本を見てください…)
import numpy as np
epsilon = 1e-5
class ICA:
def __init__(self, x):
self.x = np.matrix(x)
def ica(self): #独立成分分析
self.fit()
z = self.whiten()
y = self.analyze(z)
return y
def fit(self): #平均を0にする
self.x -= self.x.mean(axis=1)
def whiten(self): #白色化
sigma = np.cov(self.x, rowvar=True, bias=True)
D, E = np.linalg.eigh(sigma)
E = np.asmatrix(E)
Dh = np.diag(np.array(D) ** (-1/2))
V = E * Dh * E.T
z = V * self.x
return z
def normalize(self, x): #正規化
if x.sum() < 0:
x *= -1
return x / np.linalg.norm(x)
def analyze(self, z):
c, r = self.x.shape
W = np.empty((0, c))
for _ in range(c): #観測数分だけアルゴリズムを実行する
vec_w = np.random.rand(c, 1)
vec_w = self.normalize(vec_w)
while True:
vec_w_prev = vec_w
vec_w = np.asmatrix((np.asarray(z) * np.asarray(vec_w.T * z) ** 3).mean(axis=1)).T - 3 * vec_w
vec_w = self.normalize(np.linalg.qr(np.asmatrix(np.concatenate((W, vec_w.T), axis=0)).T)[0].T[-1].T) #直交化法と正規化
if np.linalg.norm(vec_w - vec_w_prev) < epsilon: #収束判定
W = np.concatenate((W, vec_w.T), axis=0)
break
y = W * z
return y次に、データの入出力をするためのコード separation.pyを作ります。
import numpy as np
import scipy.io.wavfile as wf
from ica import ICA
rate1, data1 = wf.read('mix_1.wav')
rate2, data2 = wf.read('mix_2.wav')
rate3, data3 = wf.read('mix_3.wav')
if rate1 != rate2 or rate2 != rate3:
raise ValueError('Sampling_rate_Error')
data = [data1.astype(float), data2.astype(float), data3.astype(float)]
y = ICA(data).ica()
y = [(y_i * 32767 / max(np.absolute(y_i))).astype(np.int16) for y_i in np.asarray(y)]
wf.write('music1.wav', rate1, y[0])
wf.write('music2.wav', rate2, y[1])
wf.write('music3.wav', rate3, y[2])これで、必要なものは揃ったので適当なディレクトリにこれらのコードとデータを入れてseparation.pyを実行すると分離された音源データができます。
結果
music1.wav
music2.wav
music3.wav
music1がloop1.wav、music2がfanfare.wav、music3がstrings.wavとほぼ同じに聞こえます、分離することができました。 権利関係がよくわからないのでデータを上げることはできませんが、同じようにして人の話し声なども、分離することができました。
最後に
便利なライブラリを使わないでも頑張ればなんとかなるものです。 よくわからないけどこの関数を使うとなんかできるみたいな状態の人は、一度使わないで作ろうとするとライブラリの理解が深まったりありがたさがよりわかると思います。
ライブラリを使わないからにはちゃんとした理論的な説明を書きたかったのですが、理解しきれていないところも多く適当な説明になってしまいましたが、興味を持った人は
を読んでみてください。
