
こんにちは、てれにゃんです。
Pythonを使ったTwitterスクレイピングによる心理学的検討をしたいと思います。※機械学習のことはいっさい含まれていないのでご注意ください。 自分のことを何と呼ぶかで、与える印象は大きく変わりますよね。
男性の場合で考えると、「おれ」だとより男性的で力強いイメージ、「ぼく」だと従順で腰が低いイメージといったところでしょうか。では、実際に使う一人称によって、発言自体に違いが現れてくるのでしょうか?
今回はTwitterのツイート文字数に違いがあるかを調べました。日本の男らしい男性は、あまり多くを語らないとよく言われます。「俺」「僕」はいずれも一般的に男性が使う一人称ですが、「俺」の方がより男性性の強いイメージがあります。このことから、「俺」を使う人の方がより多くを語らないのではないかと考えられます。そこで、以下の仮説を立てました。
〜仮説〜
「俺」を使う人は「僕」を使う人より1ツイートにおける文字数が少ない?
ちなみに、俺や僕を使う女性もたまにいますが、そのへんは無視して考えたいと思います。
環境&準備
- Python3系
- jupyter notebook
- Twitterアカウント
「俺」「おれ」「僕」「ぼく」を含むツイートを取得
まずはツイートを取得します。Twitterを使って分析したい場合はまずAPIを取得する必要がありますので、API取得のためのキーを持っていない方はまずこちらを参照してください。
Qlita 「Python で Twitter API にアクセス」
以下のリンクのコードをコピペすると、API切れなども考慮された挙動ができ、大変便利です。約10000件まではAPI切れせず素早く取得できました。それ以上は15分ほど待てばさらに取得可能です。
コード7区「TwitterAPI でツイートを大量に取得。サーバー側エラーも考慮(pythonで)」
サーチ単語をこのように書き換えてしまえばOKです。カタカナも含めた方が抜け漏れはありませんが、乳製品が多く拾われそうなので今回はやめました。
俺/僕判定
「俺」「おれ」「僕」「ぼく」のいずれかが含まれるツイートを取得しましたが、1ツイートの中で一人称が複数含まれる場合が考えられます。その場合、多く含まれる方を採用し、俺と僕の両方が含まれている場合は「どちらでもない」という判断をする必要があります。
以下では「俺」「おれ」が含まれていたらOREリストに1、「僕」「ぼく」が含まれていたらBOKリストに1が追加されるようになっています。ただし、俺と僕、俺とぼく、おれと僕、おれとぼくのような組み合わせの場合は、いずれのリストも0となります。
first_person は、俺が1、僕が2、その他(俺と僕が同数など)が0となるようにしています。
データの記録
下の for では、ツイートに含まれる複数情報の取得を20000回繰り返しています。取得したらただちに append を使ってリストに追加していきます。
ここでは文字数が重要になってきますので、空白や改行が邪魔になります。そのため
で空白・改行を消しました。 また、len(tweet[“text”]) で取得したテキストデータから文字数をカウントしています。
utf-8だと文字化けしてcsvでテキストを読むことができないため、utf-16にしています。
ヒストグラム
一人称ごとで文字数のヒストグラムを描いてみます。ここでは3つのヒストグラムが重なって表示されるようにしていますが、first_person = 0 は「俺」でも「僕」でもないので不必要です。そのため、とりあえず first_person = 0 のときだけ透明にして見えないようにしておきました。透明度は plt.hist() の中の alpha で調節できます。
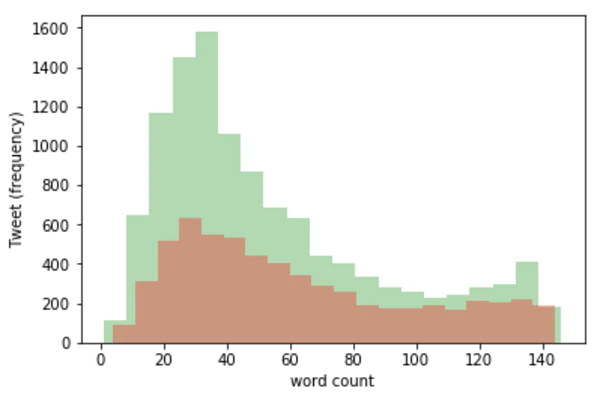
いずれの一人称も30文字あたりがピークとなっていますが、緑(俺)の方がかなり多くなっています。それに対して、ピークを過ぎてからは俺と僕で差が小さくなっています。 ぱっと見では緑(俺)の方が文字数が少ないように見えますが、そもそも緑(俺)の方がツイートが多いため、このヒストグラムではよくわかりません。そこで、正規化してもう一度ヒストグラムを出してみます。
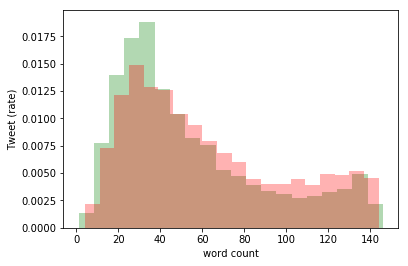
このように、上のコードに normed = True をつけたすだけで正規化できました。 縦軸は割合となり、緑と赤の合計が同じとなりました。さきほどとは異なり、60文字以上で赤(僕)が緑(俺)を上回っているのが目立ちますね。
棒グラフ
まず記述統計をしたいと思いますが、dfにはツイートの文字が含まれているため、数字を数字として扱うことができません。そのため、以下のようにnum_dfという数字だけのデータフレームを新たに作りました。
平均値および中央値は以下のように簡単に出せます。
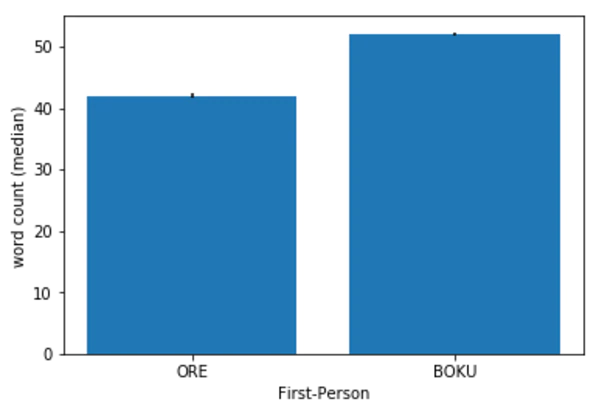
文字数について、「俺」の平均値が54.3文字、「僕」の平均値が61.6文字でした。中央値も「俺」で42文字、「僕」で52文字となり、いずれの値においても、「俺」の方が1ツイートにおける文字数が少ないという結果になりました。なお、標準誤差エラーバーもがんばって出してみましたが、小さすぎてゴミのようになってしまいました。
検定
scipy を使うことで統計的検定ができます。
ヒストグラムを見てわかるように、文字数は正規分布していないので、今回はt検定ではなくU検定をします。 俺群と僕群の間で文字数についてU検定をおこなった結果、U値が30960093.5、p < 0.05(p = 4.15e-42)で両者の差は有意となりました。
つまり、「俺」は「僕」より1ツイートにおける文字数が少ないという仮説が支持されました。2万件近くもツイートがあると、p値が5%切るのは余裕ですね。検定するまでもなく明らかです。たくさんデータをとるとp値は小さくなりますが、p値は2群間の差の大きさを表すものではないので注意してください。
まとめ
ヒストグラムと棒グラフで視覚的に確認しても、検定を行って数値で確認しても、「俺」を使ったツイートの方が「僕」を使ったツイートよりも文字数が少ないことがわかりました。「俺」を使う男らしい(印象を与える)人は口数が少なく、背中で語るような人なのかもしれませんね。
今回紹介した統計的分析手法は心理学でもよく使われる基礎的なもので、わざわざPythonを使わなくてもできそうなものです。しかし、Pythonを使うことで、Twitterで取得した大量のデータを使って気軽に遊ぶことができます。Twitter上に埋まった大量の宝をぜひPythonで掘り出してみてくださいね!
最後までご覧くださりありがとうございました。
