注意:このページはPC版で見ることを推奨します。
精度の高い手書き文字認識
突然ですが、皆さんはスマホの手書き入力を使った事がありますか?有名なもので言うと、Googleの手書き文字入力アプリがあります。私は今初めて使ってみたのですが、このアプリの精度の高さに感動しています。
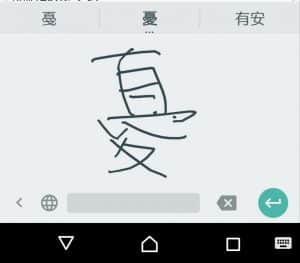
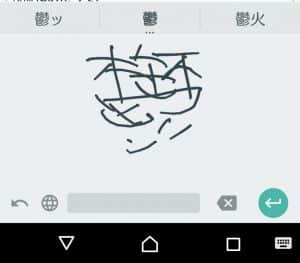
画像1: 「憂鬱」という字を書いた。崩れていても、ちゃんと書いていなくても認識してくれる。字が汚すぎる。
この手書き文字認識は、「深層学習」というAIの技術によって制度を格段に上げられました。
深層学習についてはひとまず置いておいて、早い話が手書き文字認識は深層学習の分野ということです。
深層学習を用いないで手書き文字認識を実現してみたい
さて、この技術、もっと単純な学習によって実装できないだろうか?
個人的に気になったので、単純なものなら深層学習を用いない機械学習でも実装できるかどうかを検証してみたいと思います。
方針としては、
画像のピクセル毎の明暗データを説明変数とし、画像に書かれている数を目的変数にすることで機械学習のモデルに適用させる
という感じです。
検証にあたって、
手書きの数字1文字が何であるかを判断するプログラム”Handwrite_recognition.py”を実装しました。
機械学習で手書き文字認識のプログラム
使用言語はpython3系
使用したパッケージは
- scikit-learn(sklearn): 機械学習のモジュール。今回の肝
- pillow(PIL): 画像データ処理のモジュール。
- os: ディレクトリの操作を簡単にするモジュール。
- numpy(np): 配列計算の効率化モジュール。
これだけです。カンタン!
今回の実装の目的は、
- sklearnのデータセットを使って機械学習をする
- 深層学習を用いずに手書きの数字を判別する
- PILを使って画像データを加工する
この3つです
それでは早速、コードを順を追って見ていきましょう。
パッケージのインポート
import os
import numpy as np
from PIL import Image
import sklearn
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
ここではsklearnから
- 手書き文字のデータ(load_digits)
- ロジスティック回帰のモジュール(LogisticRegression)
- 教師データの分割をするモジュール(train_test_split)
をインポートします。
画像データ読み込み、加工
filenames = sorted(os.listdir('handwrite_numbers'))
img_test = np.empty((0, 64))
for filename in filenames:
img = Image.open('handwrite_numbers/' + filename).convert('L')
resize_img = img.resize((64, 64))
img_data256 = np.array([])
for y in range(8):
for x in range(8):
crop = np.asarray(resize_img.crop(
(x * 8, y * 8, x * 8 + 8, y * 8 + 8)))
bright = 255 - crop.mean()**2 / 255
img_data256 = np.append(img_data256, bright)
min_bright = img_data256.min()
max_bright = img_data256.max()
img_data16 = (img_data256 - min_bright) / (max_bright - min_bright) * 16
img_test = np.r_[img_test, img_data16.astype(np.uint8).reshape(1, -1)]
画像はあらかじめ正方形のサイズのものを用意しておき、読み込んだものを8×8の64画素、16段階の白黒反転グレースケールにします。
教師データと形式を一致させるために、画像一枚を64次元の配列にしてデータにしているというわけです。
画像の中の一番明るい部分が16、一番暗い部分が0になるような計算を挟むことでsklearnのデータセットとかたちを同じにしています。
ちなみに、加工した64画素の画像はこんな感じ

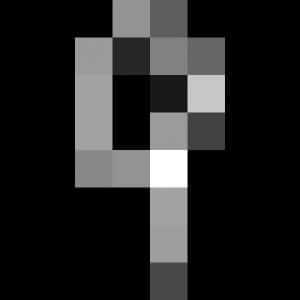
画像2: 手書き文字の画像を読み込んで、データセットに合う型に加工する。
教師データから学習
digits = load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=0)
logreg = LogisticRegression()
logreg_model = logreg.fit(X_train, y_train)
print('教師データのスコア:', logreg_model.score(X_train, y_train))
print('テストデータのスコア:', logreg_model.score(X_test, y_test))
内容自体はシンプルです。
sklearnに付属している手書き文数字のデータセットを教師データにします。
教師データを読み込み、そのうちの半分を使って学習します。logreg_modelは教師データから学習したモデルになるので、あとはこのモデルを使うだけです。
ここで教師データを半分にした理由は、過学習を少しでも予防するためです。似通った教師データばかり与えてしまうと、新規のデータに対応できなくなってしまうのです。このことを汎化能力の低下といいます。今回テストしてもらうデータは少し左にずれていたりするので、真ん中揃いのデータばかりで学習されては汎化能力が下がってしまいます。
“スコア”はモデルのデータに対する精度です。教師データからどれほど学習できたかを確認するため、学習結果を出力します。
機械学習の方法については検証の必要性もあるでしょうが、今回はよく例として取り上げられるロジスティック回帰のインスタンスを使ってみました。
画像データの判別
X_true = []
for filename in filenames:
X_true = X_true + [int(filename[:1])]
X_true = np.array(X_true)
pred_logreg = logreg_model.predict(img_test)
print('判別結果')
print('観測:', X_true)
print('予測:', pred_logreg)
print('正答率:', logreg_model.score(img_test, X_true))
logreg_model.predict()にデータを放り込むと、判別した結果を返します。楽ちん!
ついでに正答率も見ておきたいので、あらかじめ画像ファイル名の頭文字を中身の数字にしておいて、正解とのスコアを出せるようにしています。
以上になります。まとめたものは下の方に置いてあります。
それでは動かしてみましょう。
実際に手書き文字を読み込んで判別してもらう
今回判別してもらう数字はこちらです。1,4,7は三種類の書き方を用意しました。

画像3: 用意した手書き文字。スマホで書いた。字が汚すぎる。
画像をこのプログラムがあるフォルダ内の”handwrite_numbers”というフォルダに入れ、
ターミナルからこのプログラムを動かすと
$ python3 Handwrite_recognition.py
教師データのスコア: 0.998886414254
テストデータのスコア: 0.944382647386
判別結果
観測: [0 0 0 1 1 1 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 8 8 8 9 9 9]
予測: [0 0 0 6 1 1 1 2 1 1 3 4 4 4 4 5 4 1 6 6 6 7 7 0 8 1 4 9 4 9]
正答率: 0.633333333333
こうなりました。
“観測”が実際の値、”予測”がプログラムによって判断された値です。
“テストデータのスコア”を見ると、学習した時点での精度は高い様です。
ただ、”観測”、”予測”の部分を見ると、今回用意した30文字のうち11文字は誤って判別されています。
3文字に1文字は間違ってます。
こう見ると、どうやら過学習気味ですね。
・・・うーん。
2,3,5,8の精度が低いなぁ。
右に膨らんでいる文字の識別が苦手なのでしょうか。
まあでも、思ったよりはきちんと働いてくれました。
結果
ある程度簡単な内容であれば、深層学習を使わずとも手書き文字を認識するのは可能(ただし精度は高くない)
ただ、今回の実装には問題点があり、
自前の教師データを用意できないのでモデルの汎化能力が下がる
サイズが正方形でない画像に対応していない
文字の大きさ、線の太さによっては字が潰れてしまい、判別が困難に
この2点が挙げられます。
まとめ
機械学習による文字認識の天敵は、
であると言える。
もっと精度は上げたいですね。
次回は深層学習を用いて、もっとマトモな手書き文字認識を実装したいと思います。
今回作成したスクリプト
import os
import numpy as np
from PIL import Image
import sklearn
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
"""
------------------------------------------------------------------
"""
filenames = sorted(os.listdir('handwrite_numbers'))
img_test = np.empty((0, 64))
for filename in filenames:
img = Image.open('handwrite_numbers/' + filename).convert('L')
resize_img = img.resize((64, 64))
img_data256 = np.array([])
for y in range(8):
for x in range(8):
crop = np.asarray(resize_img.crop(
(x * 8, y * 8, x * 8 + 8, y * 8 + 8)))
bright = 255 - crop.mean()**2 / 255
img_data256 = np.append(img_data256, bright)
min_bright = img_data256.min()
max_bright = img_data256.max()
img_data16 = (img_data256 - min_bright) / (max_bright - min_bright) * 16
img_test = np.r_[img_test, img_data16.astype(np.uint8).reshape(1, -1)]
"""
------------------------------------------------------------------
"""
digits = load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=0)
logreg = LogisticRegression()
logreg_model = logreg.fit(X_train, y_train)
print('教師データのスコア:', logreg_model.score(X_train, y_train))
print('テストデータのスコア:', logreg_model.score(X_test, y_test))
"""
------------------------------------------------------------------
"""
X_true = []
for filename in filenames:
X_true = X_true + [int(filename[:1])]
X_true = np.array(X_true)
pred_logreg = logreg_model.predict(img_test)
print('判別結果')
print('観測:', X_true)
print('予測:', pred_logreg)
print('正答率:', logreg_model.score(img_test, X_true))

