こんにちは!アイデミーの渡部です!
今回の「やってみた!」では、ディープラーニングで画像判別器を製作したいと思います!
(実は、1年半くらい前に、グラスの分類器を作ったことがあります。その時の精度は、80%ギリギリ行かなかったくらいでした。。前回の記事はこちら)
さて、今回のテーマですが、題名にもある通り、「馬」と「シマウマ」の判別器をつくってみた!というのをやります!巷で有名なお題として、kaggleの犬と猫の判別があるんですが、それと同じくらい似ている動物を分類できるのか試してみます!精度は、前回よりも高いものを作ります!分類器がシマシマをうまく判別できるかどうか楽しみです!
また、今回は久しぶりにPythonを触るということもあり、一旦、最後までやってみて、その後、精度を上げるための改善をしていこうと考えています。自分もこれから改めて機械学習の勉強をしようと思いますので、お手柔らかに見ていただけたらありがたいです!
実行環境
- Python3 3.6.3
- jupyter notebook 4.3.0
- MacOS Catalina バージョン10.15.7
- NumPy 1.16.2
データ収集
「データは石油」であると喩えられるほど重要であるデータですが、実際に、企業のプロジェクトなどでAIを使う際には何万、何十万といった膨大な量のデータが必要であると言われています。
ただ、個人でそこまでのデータ量を集めるのは困難であることが多いです。前回の私の挑戦の際もグラスそれぞれに対して400枚ほどしか集められませんでした。精度があまり上がらなかったのもデータ量の少なさが一つの要因であるとも考えられるので、今回は、1000枚ずつ画像を集めたいと思います。
さて、今回もflickrから画像データを収集します。flickrとは、写真の共有を目的としたコミュニティウェブサイトのことです。
画像データを一枚一枚ダウンロードするのは最初から画像を厳選できるものの、大量の画像を集めたい場合には効率が悪いです。そのため、今回は、flickrAPIを用いて、大量の馬、シマウマの画像を自動でフォルダに保存できるようにしたいと思います。これをスクレイピングといいます。
ソースコードは以下です。今回は、できるだけサーバーの負荷にならないように1回につきスクレイピングする枚数は500枚にしました。
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
from pprint import pprint
import os,time
key = '自分のキー'
secret = '自分のシークレットキー'
wait_time = 1
def get_photos(animal_name):
savedir = './' + animal_name
flickr = FlickrAPI(key, secret, format='parsed-json')
result = flickr.photos.search(
text = animal_name,
per_page = 500,
media = 'photos',
sort = 'relevance',
safe_search = 1,
extras = 'url_q, license'
)
photos = result['photos']
print(photos['photo'])
for i, photo in enumerate(photos['photo']):
try:
url_q = photo['url_q']
except:
print('取得に失敗しました')
continue
filepath = savedir + '/' + photo['id'] + '.jpg'
if os.path.exists(filepath): continue
urlretrieve(url_q, filepath)
time.sleep(wait_time)
start = time.time()
get_photos('horse')
get_photos('zebra')
print('処理時間', (time.time() - start), "秒")
データクレンジング
さて、「horse」と「zebra」のフォルダにそれぞれ集めた約1000枚の画像データから、質の悪いデータを手作業で消去していきます。主に、判断基準は自分が馬かシマウマか判別できるものとします。結構甘々で行きます。
削除後は以下のようになりました。前回の「グラスの判別」の時よりも質の良いデータが集まっていたおかげで、削除する枚数が少なくてすみました。結果がとても楽しみです!
horseフォルダ:1000枚→969枚
zebraフォルダ:1000枚→957枚
データをNumpy形式に変換
ここでは、画像データはそのままでは扱えないため、画像データを扱いやすいNumpy形式の64×64の3チャンネルに変換してから、学習用データと評価用データに割り振ります。比率は、前回と同じく7:3にしました。
from PIL import Image
import os,glob
import numpy as np
from sklearn import model_selection
classes = ['horse', 'zebra']
num_classes = len(classes)
image_size = 64
X = []
Y = []
for index, class_ in enumerate(classes):
photos_dir = './' + class_
files = glob.glob(photos_dir + '/*.jpg')
for i, file in enumerate(files):
if i >= 1000: break
image = Image.open(file)
image = image.convert('RGB')
image = image.resize((image_size,image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
X = np.array(X)
Y = np.array(Y)
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,Y,test_size=0.3)
xy = (X_train,X_test,y_train,y_test)
np.save('./animal.npy', xy)
モデルの構築・学習・評価
前回のモデルをベースに、以下のように構築しました。今回新たに追加したのは、学習曲線の可視化プログラムです。model.fitの引数にvalidation_dataを渡してあげることで実装ができます。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
import numpy as np
import keras
import matplotlib.pyplot as plt
classes = ['horse', 'zebra']
num_classes = len(classes)
image_size = 64
def main():
X_train,X_test,y_train,y_test = np.load('./animal.npy')
X_train = X_train.astype('float') / 255
X_test = X_test.astype('float') / 255
y_train = np_utils.to_categorical(y_train,num_classes)
y_test = np_utils.to_categorical(y_test,num_classes)
model = model_train(X_train,y_train,X_test,y_test)
model_eval(model,X_test,y_test)
def model_train(X_train,y_train,X_test,y_test):
model = Sequential()
model.add(Conv2D(32,(3,3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation('softmax'))
opt = keras.optimizers.rmsprop(lr=0.00005,decay=1e-6)
model.compile(loss='categorical_crossentropy',
optimizer=opt,metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=32,epochs=100,validation_data=(X_test,y_test))
model.save('./animal_cnn.h5')
graph_general(history)
return model
def model_eval(model,X_test,y_test):
scores = model.evaluate(X_test,y_test,verbose=1)
print('Test Loss: ', scores[0])
print('Test Accuracy: ', scores[1])
def graph_general(history):
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train_acc', 'Test_acc'], loc='upper left')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train_loss', 'Test_loss'], loc='upper left')
plt.show()
if __name__ == '__main__':
main()
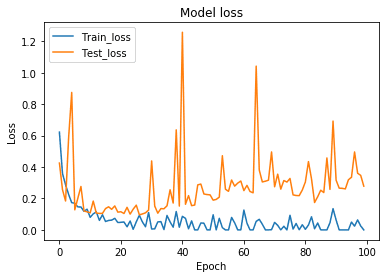
まずは、epoch100で試したところ、Test Accuracyは約0.97、Test Lossは約0.28となりました。ニューラルネットワークの学習においての目標は、出力と正解のラベルの差を意味する loss を最小化することにあります。
:
:
:
Epoch 95/100
1346/1346 [==============================] - 26s 19ms/step - loss: 4.7557e-07 - acc: 1.0000 - val_loss: 0.3189 - val_acc: 0.9671
Epoch 96/100
1346/1346 [==============================] - 26s 19ms/step - loss: 0.0498 - acc: 0.9933 - val_loss: 0.3352 - val_acc: 0.9689
Epoch 97/100
1346/1346 [==============================] - 25s 18ms/step - loss: 0.0241 - acc: 0.9955 - val_loss: 0.4963 - val_acc: 0.9498
Epoch 98/100
1346/1346 [==============================] - 25s 19ms/step - loss: 0.0636 - acc: 0.9933 - val_loss: 0.3606 - val_acc: 0.9654
Epoch 99/100
1346/1346 [==============================] - 26s 19ms/step - loss: 0.0253 - acc: 0.9978 - val_loss: 0.3471 - val_acc: 0.9585
Epoch 100/100
1346/1346 [==============================] - 27s 20ms/step - loss: 6.6260e-05 - acc: 1.0000 - val_loss: 0.2786 - val_acc: 0.9689
578/578 [==============================] - 4s 6ms/step
Test Loss: 0.27856635378045674
Test Accuracy: 0.9688581314878892
学習曲線をみてみましょう。epoch40くらいからtest_lossが上昇していき、train_lossと乖離していく様子が確認でき、過学習していると考えられます。ですので、epochを乖離が始まる直前の40に設定して、もう一度、学習させます。
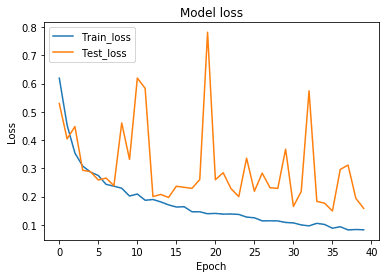
改めて学習させると、以下のようになります。Test Accuracyの高さを維持しつつ、先ほどよりもTest Lossを低くすることに成功しています。先ほどの学習曲線のグラフの振り幅の大きさは気になりますが、十分な精度が出ているので、分類器はこれで一旦完成とします。
:
:
:
Epoch 35/40
1346/1346 [==============================] - 24s 18ms/step - loss: 0.1013 - acc: 0.9599 - val_loss: 0.1765 - val_acc: 0.9343
Epoch 36/40
1346/1346 [==============================] - 24s 18ms/step - loss: 0.0881 - acc: 0.9673 - val_loss: 0.1492 - val_acc: 0.9464
Epoch 37/40
1346/1346 [==============================] - 24s 18ms/step - loss: 0.0934 - acc: 0.9591 - val_loss: 0.2959 - val_acc: 0.9031
Epoch 38/40
1346/1346 [==============================] - 24s 18ms/step - loss: 0.0821 - acc: 0.9703 - val_loss: 0.3116 - val_acc: 0.9014
Epoch 39/40
1346/1346 [==============================] - 24s 17ms/step - loss: 0.0835 - acc: 0.9681 - val_loss: 0.1937 - val_acc: 0.9256
Epoch 40/40
1346/1346 [==============================] - 23s 17ms/step - loss: 0.0826 - acc: 0.9681 - val_loss: 0.1583 - val_acc: 0.9429
578/578 [==============================] - 3s 6ms/step
Test Loss: 0.15832428274527965
Test Accuracy: 0.9429065743944637
任意の画像を分類&Grad-CAMを実装!
分類器が出来上がったので、実際に任意の画像を読ませて、しっかり分類できるのか試して見ます。また、今回は、上記で作成したモデルに、Grad-CAMを実装します。Grad-CAMを実装すると、モデルが画像を分類をするために、画像のどこに注目しているのかわかるので、モデルの欠陥の発見や考察がしやすいです!(ここが個人的に1番好きです!)
また、任意の画像のパスを入力すると、保存したモデルから馬とシマウマのどちらか分類をしてくれるプログラムを作成しました。
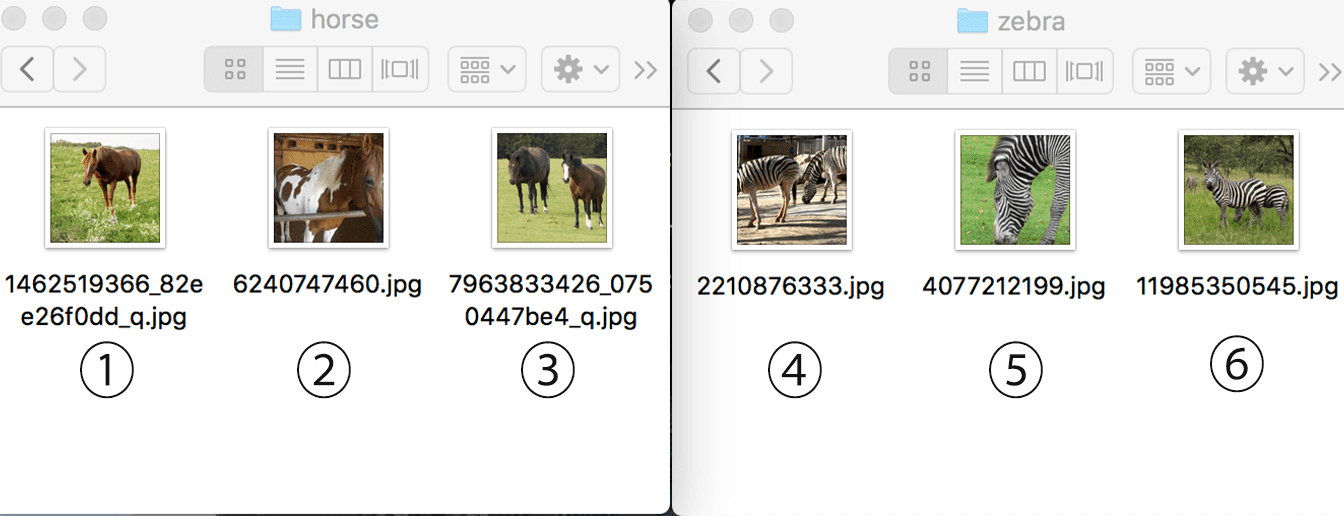
testフォルダを用意して、その中にhorseフォルダとzebraフォルダを新たに作ります。それぞれ3枚ずつモデルのテストをしてみます!(この後、紹介する際にわかりやすいので、それぞれ番号を振っておきました。)
from keras.models import load_model
import matplotlib.pyplot as plt
from PIL import Image
import os,glob
import numpy as np
from sklearn import model_selection
img_size = 64
test_img = "./test/zebra/4077212199.jpg"
model_param = "./animal_cnn.h5"
def load_image(img_path):
img = Image.open(img_path)
img = img.convert('RGB')
img = img.resize((img_size, img_size))
img = np.asarray(img)
img = img / 255.0
return img
model = load_model(model_param)
img = load_image(test_img)
pred = model.predict(np.array([img]))
print(round(pred[0][0] / 1.0, 3) *100 , "%", round(pred[0][1] / 1.0, 3) *100 , "%" )
ans = np.argmax(pred, axis=1)
if ans == 0:
print(">>> 馬")
elif ans == 1:
print(">>> シマウマ")
テスト1
まず、馬の1枚目の画像ですが、うまく分類することができました!
下記のコードブロックは、入力サンプル画像に対する予測値の出力です。分かりやすいように%表示にしました。
画像は、Grad-CAMによる、イメージのどの部分が分類に重要であるかを示したものです!色が濃いほど、分類に大きく影響しています。これを見てみると、馬全体に注目していて、特に頭部に最も大きく影響していることが分かります!

“Friendly Horse” by William Garrett is licensed under CC BY 2.0
テスト2
こちらの画像もうまく分類できていますね。下の画像では、馬の頭に注目していることが分かります。今回の馬のデータにはこのように白い模様が入っているものは例外的なので、テスト1とは違い、胴体部分には注目していないのかもしれません。ですが、模様のない頭部に注目して、正確に分類できています。

“Horse” by Itai Nathaniel is licensed under CC BY 2.0
テスト3
3枚目の画像は馬が2頭写っています。精度は、テスト1、2に比べると少しだけ下がりましたが、それでもうまく分類できています。それぞれ、胴体を中心に注目していますね!
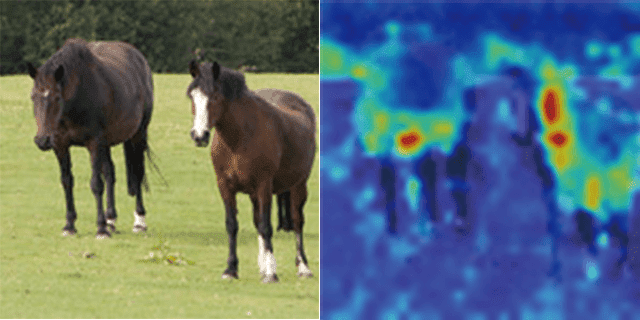
“horses” by Barry Skeates is licensed under CC BY 2.0
テスト4
シマウマの1枚目の画像です。胴体の縞部分に注目しています!精度も文句なしです。

“Zebra” by snarglebarf is licensed under CC BY 2.0
テスト5
5枚目の画像です。こちらも複数頭写っている画像になります。他のテストに比べて、精度が少し下がってしまいましたが、正しく分類できています!

“Zebra” by 48376342@N00 is licensed under CC BY 2.0
テスト6
最後の画像です。精度は文句なしです。こちらもシマウマの縞の部分に全体的に注目していることが分かります!Grad-CAMを実装し、いくつかの画像を確認してみましたが、分類器は、高い精度で馬とシマウマの判別できているようですね!
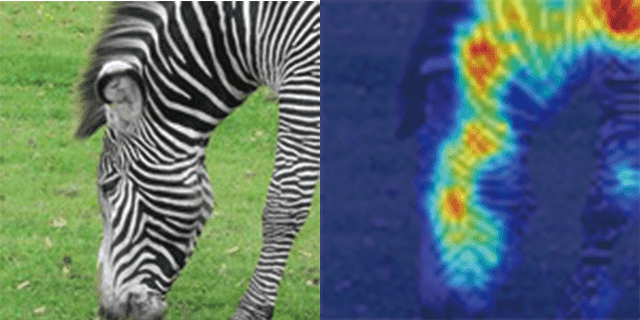
“Zebra” by Shazron is licensed under CC BY 2.0
感想
今回は精度の高い分類器を作ってみたいという思いで始めたのですが、それに関しては最終的に94%という高い精度を出すことができて良かったです!達成できた要因の一つとして、データの量を増やしたことが挙げられると考えます。前回に比べて6倍も多くの画像を使用したことは、モデルの精度を上げるのに役立ったに違いないと思うからです。
ただ、今回は馬とシマウマを判定するといういわゆる2値分類だったので、適当にやっても2分の1で当たってしまうので、分類器が単純に当てやすかったということも少なからずあったかと思います。
それでも、Grad-CAMを用いて、注目している箇所を可視化した際の、馬の胴体に大きな模様がある場合には、頭に注目していたことなど、分類器としての優秀を感じた場面もありました。
次回は、今回作成した分類器をWebアプリ化したいと思います!自分も初めての試みですが、python以外にHTMLやCSSなどの言語を使う場面もあるはずなので、とても楽しみです!それでは、また次回!
最後までご覧いただきありがとうございました。

